
0x00 写在前面
前一篇文章提到,RSSHub 可以为诸多网站提供生成 RSS 订阅链接,但是除了目前已经适配了的网站以外,还有更多的网站是没有适配的。对于这些网站,可以发到 RSSHub 在 Github 上的 issue 区来请求各位开发者进行适配,不过与其做个伸手党,还不如自己动手,丰衣足食。所以接下来我就介绍一下,如何为各类网站适配 RSSHub 路由。
这个“任意网站”和“各类网站”不包括某些防爬虫防盗的网站(比如某些知识付费平台),要实现 RSSHub 路由的适配,首先你得确定你有权限来访问这个网站。
0x01 了解需要适配的网站
我以我学校的教务处官网 http://jwc.ncu.edu.cn/ 为例。打开这个网站,看看哪个地方的内容是需要的:
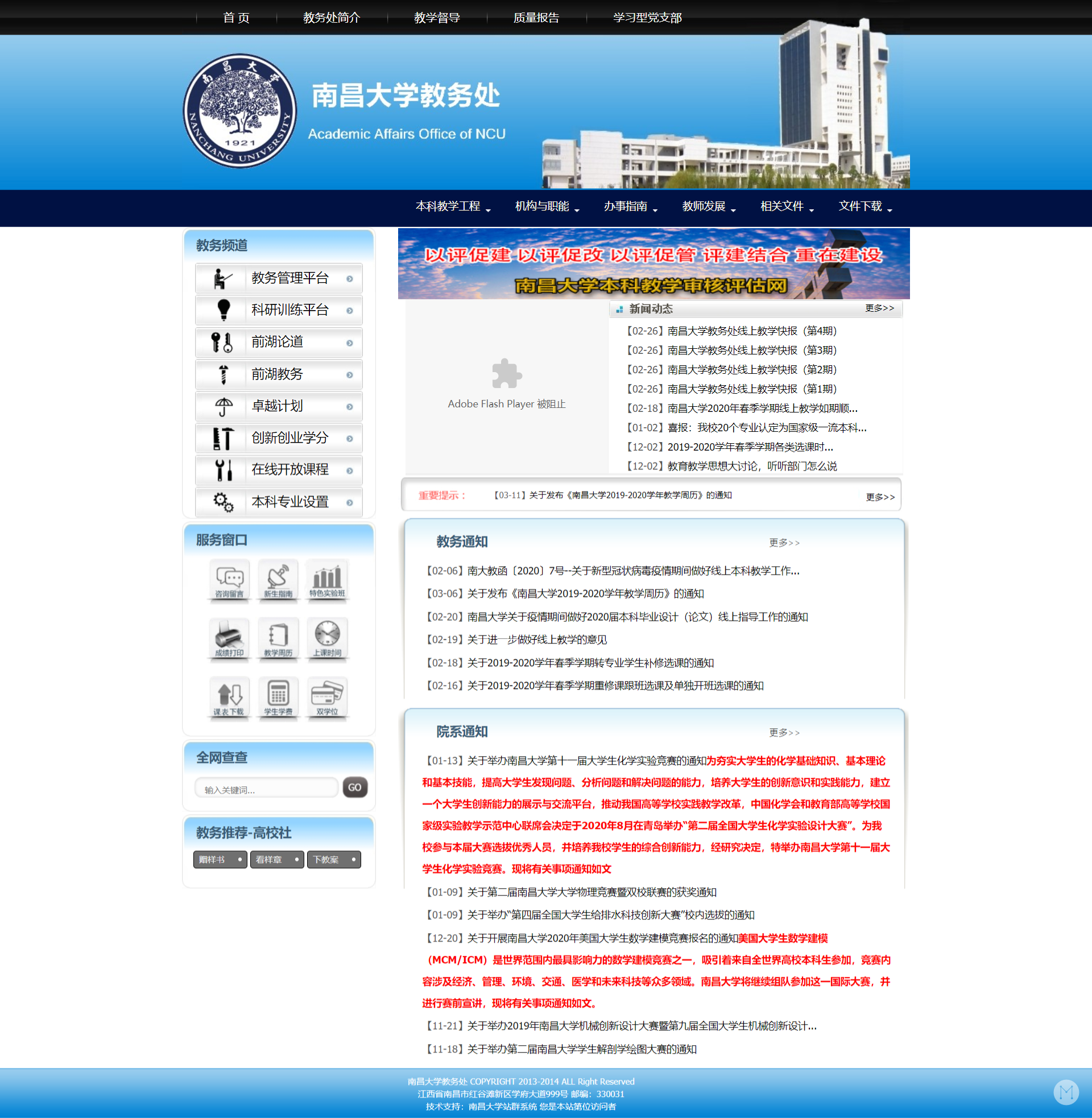
可以看到,里面有个“教务通知”和“院系通知”,这就是我想要通过 RSSHub 提取的内容。不过这里的内容还有点少,教务通知和院系通知都只显示了六条,加起来就是只有 12 条。不如点开那个“更多”试试:
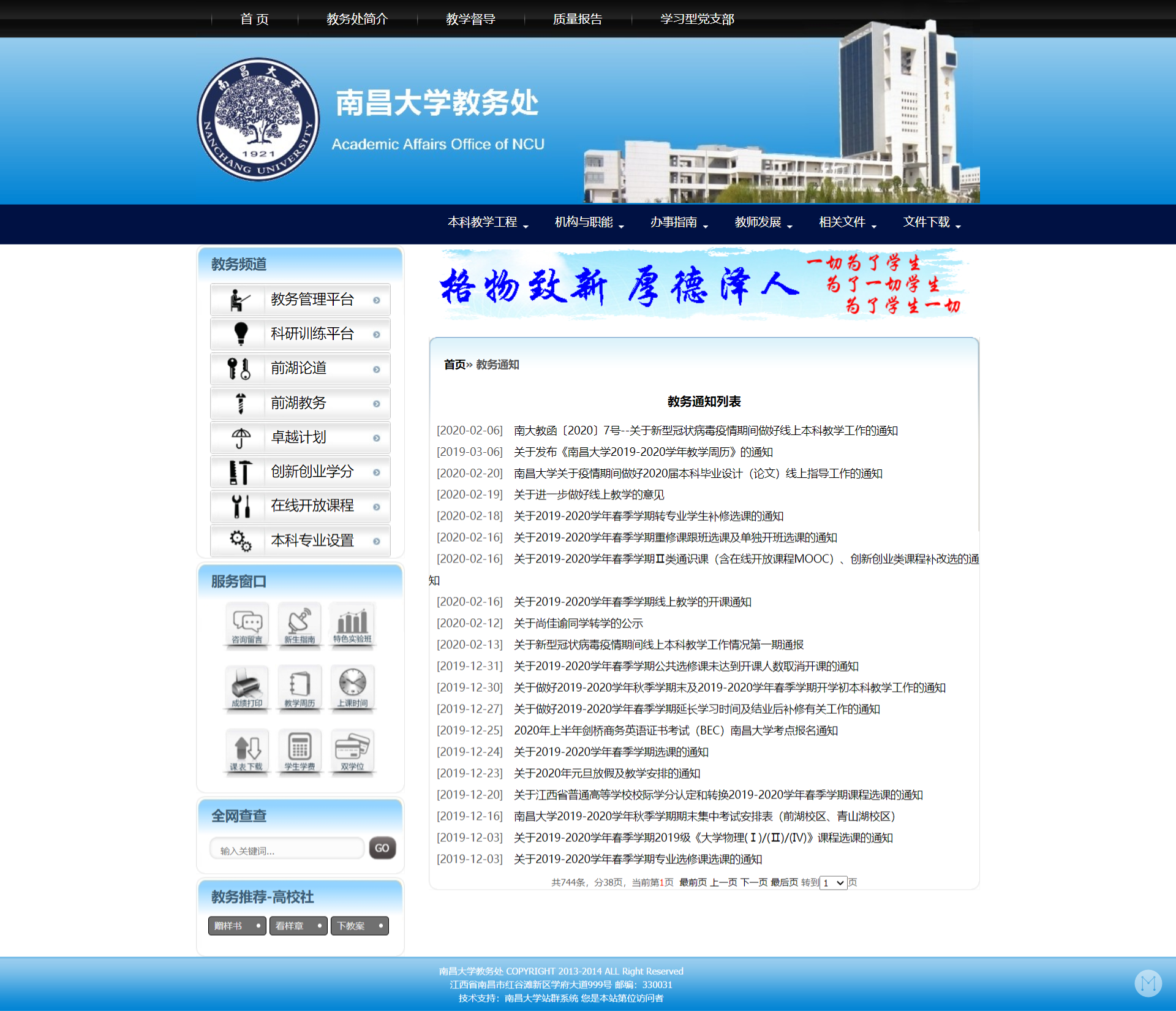
可以看到,现在一个页面里的内容要多了许多。因此我初步计划,将教务处的官网分为“教务通知”和“院系通知”两部分,对应的链接是:
那么,我要做的工作就是,让 RSSHub 找到这两个网页,然后把网页里的文章列表中的链接提取出来,再根据这些文章的链接,挨个去访问这些页面,这样就能把网页上的文章转换成 RSSHub 的订阅链接了。
0x02 添加一个路由
RSSHub 已经提供一个适配指南: https://docs.rsshub.app/joinus/#ti-jiao-xin-de-rsshub-gui-ze
先不用管什么调试不调试的,找到应该在哪里添加路由比较重要。看到官方文档中说,“在 /lib/router.js 里添加路由”,那当然是先去找到 lib/router.js 里看看咯:
nano RSSHub所在的目录/lib/router.js然后你就会看到一大串代码:
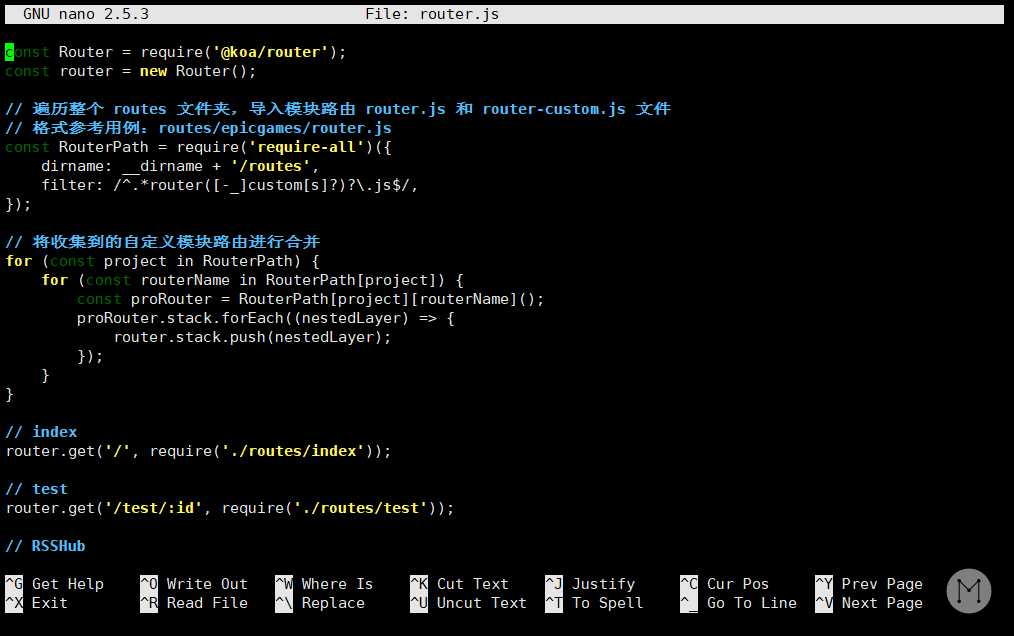
这里的代码其实都是告诉你,如果访问了对应的链接,应该去哪里找哪个模块来处理。举个例子,看到这样一行代码:
router.get('/weibo/search/hot', require('./routes/weibo/search/hot'));它就告诉你,当你访问 https://你的域名/weibo/search/hot 时,会交给 lib/routes/weibo/search/hot.js 这个模块来处理。
而看看这样的一行代码:
router.get('/weibo/keyword/:keyword', require('./routes/weibo/keyword'));这里看到,好像有个 keyword 前面多了个冒号,变成了 :keyword。这样其实表示这是个参数,也就是说,这里传入一个参数,然后 lib/routes/weibo/keyword.js 这个模块就可以读取到这个参数。
对照一下官方文档看看:
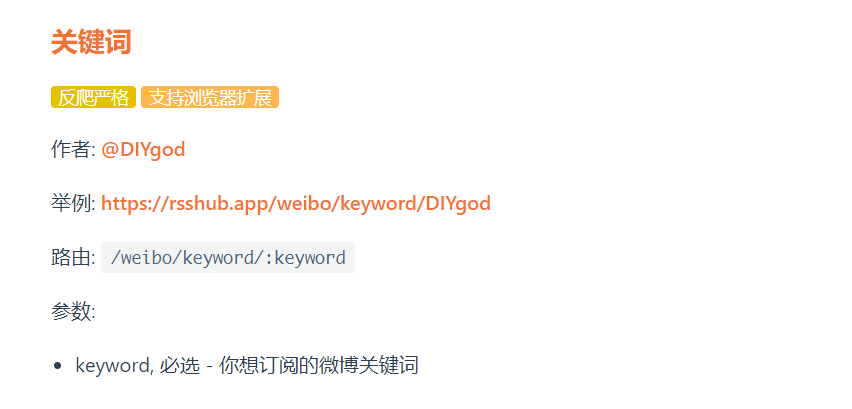
:keyword 就是表示这里是个参数那么,知道了这个路由是怎么写的,接下来就也在当前这个文档(lib/router.js)中添加下面这几行:
// 南昌大学
router.get('/ncu/jwc/:type?', require('./routes/universities/ncu/jwc'));这里加个问号,变成 :type?,表示这个参数可有可无。而后面则表示我会创建 lib/routes/universities/ncu/jsc.js 这个模块来处理教务处的内容。
至于为什么放在 universities 这个文件夹里?那当然是因为大家都放在这里啊:
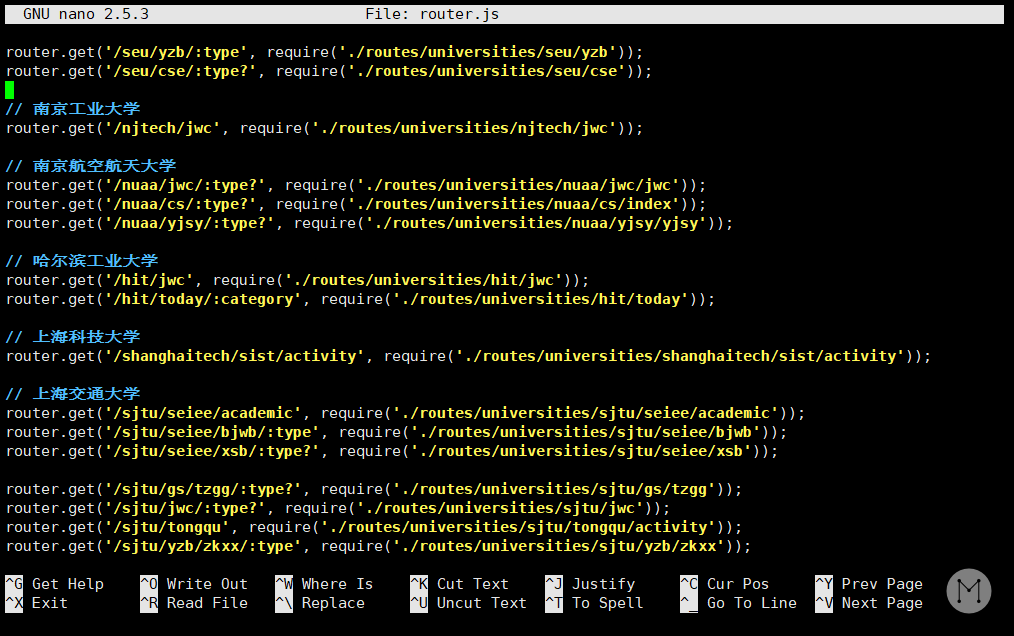
保存一下刚刚编辑的内容,然后创建 jwc.js 这个文件。在终端输入:
cd RSSHub所在的目录/lib/routes/universities
mkdir ncu
nano jwc.js0x03 实现网页信息的抓取
打开了 jwc.js 文件后,先输入这样一些内容:
const got = require('@/utils/got');
const cheerio = require('cheerio');
const url = require('url');
// 域名
const host = 'http://jwc.ncu.edu.cn';
// 分类
const map = {
jwtz: '/jwtz',
yxtz: '/yxtz',
};前面三行表示要导入这些模块,这些模块都是 RSSHub 来抓取网站信息的最基本的模块。host 常量则定义了教务处官网的域名。另一个常量 map 则定义了以下分类,前面提到过,我打算为教务处适配两种类型:
你可以看到,这个 map 其实就是定义了,在 jwc.ncu.edu.cn 后面的内容。这里我没有加上 index.htm,因为不加上它也找得到。要加上也可以,但没必要。
接着就是要构造一个导出的模块了。接着写:
// 刚才输入的内容,节约空间,这里就不写出来了
module.exports = async (ctx) => {
// 这里获取到传入的参数,也就是 /ncu/jwc/:type? 中的 type
// 通过 || 来实现设置一个默认值
const type = ctx.params.type || 'jwtz';
// 要抓取的网址
const link = host + map[type] + '/index.htm';
// 要输出的文章内容保存到 out 中
const out = await Promise.all(
// 抓取操作放这里
);
// 设置分类的标题
let info = '教务通知';
if (type === 'yxtz') {
info = '院系通知';
}
// 访问 RSS 链接时会输出的信息
ctx.state.data = {
title: '南昌大学教务处 - ' + info,
link: link,
description: '南昌大学教务处 - ' + info + ' jwc.ncu.edu.cn',
item: out,
};
}现在已经完成了一个基本的框架了。ctx.state.data 就是最终输出的数据,它定义了访问这个 RSS 订阅链接的时候会显示的信息。例如,这个订阅的标题叫做“南昌大学教务处 – 教务通知”或者“南昌大学教务处 – 院系通知”,原网站的链接是由 link 提供的,RSS 链接的描述信息是“南昌大学教务处 – 教务通知 jwc.ncu.edu.cn”,最终输出的每篇文章的内容都放在 out 里。
那么很显然,接下来的重点就是怎么从网页里抓取有效的信息了。先看看要抓取的网页,也就是 http://jwc.ncu.edu.cn/jwtz/index.htm
可以看到,在页面中提供了一个所有文章的链接列表。点击这个列表中的链接,就会自动跳转到这个页面中。不难想到,如果我要抓取这个页面中的所有文章,我应该读取这个列表中的所有文章链接,然后通过一个循环,让程序逐个访问这些文章链接,到这些文章中去抓取具体内容。
那么问题就在于怎么通过程序来读取这个列表中的所有文章链接。现在右键单击链接,选择最下边的“检查”。
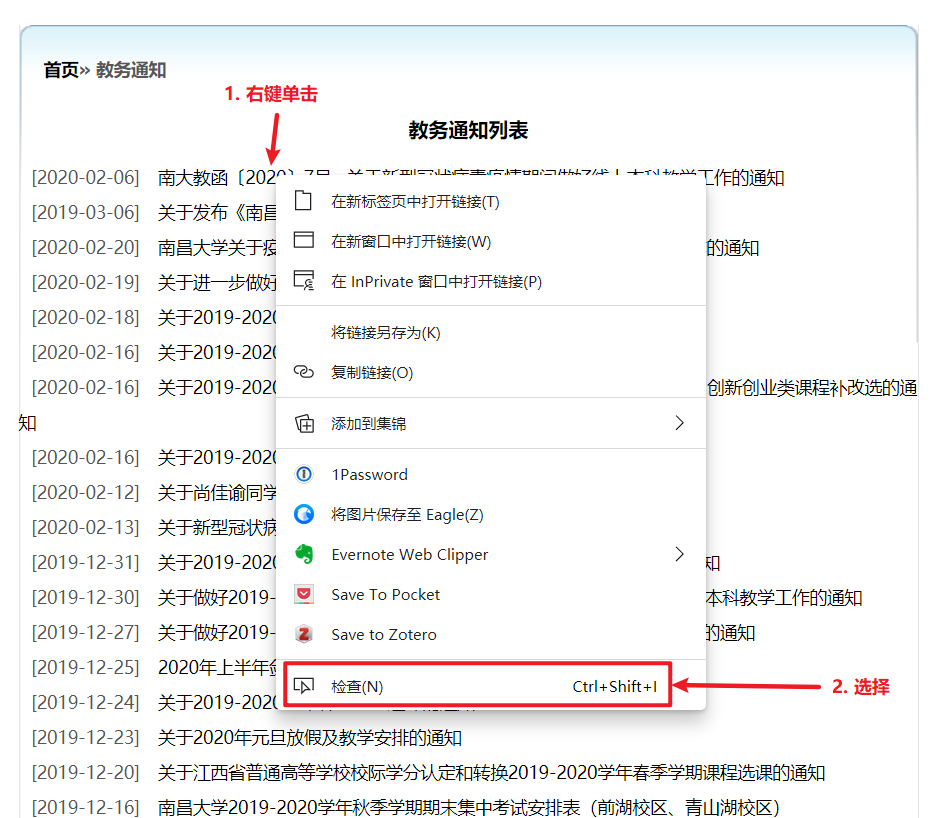
就可以看到这个链接对应的具体 HTML 代码了,例如这里的链接对应的 HTML 代码如下:
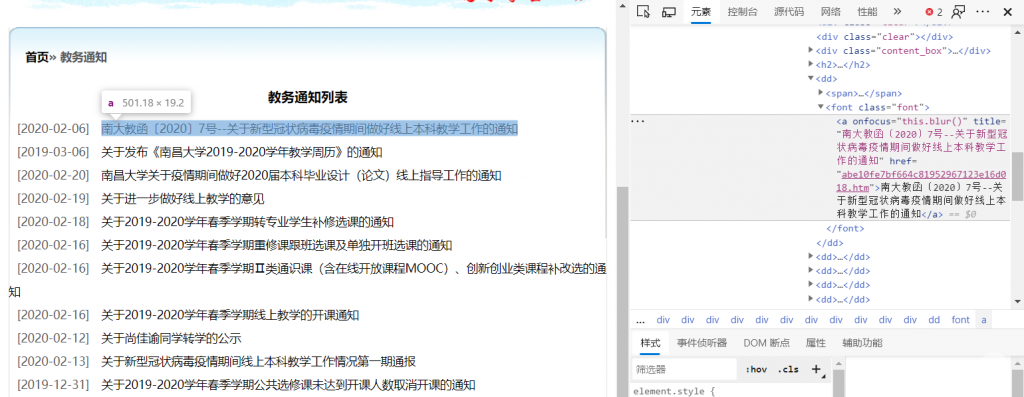
可以看到,这个链接标签 <a> 是被一个 <font> 标签包围的,并且这个 <font> 标签的 class 是 .font。因此,初步的构想是,把这个网页中的所有 .font 类下的 <a> 标签提取出来,然后去获取它的 href 属性。
通过下面这样的代码来获取所有文章链接:
// 这里没变,省略
module.exports = async (ctx) => {
// 这里也没变
const type = ctx.params.type || 'jwtz';
const link = host + map[type] + '/index.htm';
// 新增下面这一段
// ↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓
// ↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓ 下面是新增的 ↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓
// ↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓
// 获取列表页,也就是发出请求,来获得这个文章列表页
const response = await got({
method: 'get', // 请求的方法是 get,这里一般都是 get
url: link, // 请求的链接,也就是文章列表页
});
// 用 cheerio 来把请求回来的数据转成 DOM,方便操作
const $ = cheerio.load(response.data);
// 提取列表项
const urlList = $('.font') // 筛选出所有 class=".font" 的内容
.find('a') // 找到所有 <a> 标签,也就是文章的链接
.slice(0, 10) // 获取 10 个,也可以把它调大一点,比如 15 个。最大的个数要看这个网页中有多少条
.map((i, e) => $(e).attr('href')) // 作为键值对来存储 <a> 标签们的 href 属性
.get();
// ↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑
// ↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑ 上面是新增的 ↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑
// ↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑
// 下面的代码没有变化,为了简写,用 ... 表示了里面的内容
const out = await Promise.all(...);
let info = '教务通知';
if (type === 'yxtz') {...}
ctx.state.data = {...};
}现在,通过 got 模块来获取到了网页,通过 cheerio 模块提取出了所有文章的链接列表,并把这些链接存储在 urlList 中。接下来要做的,就是去访问这些链接,把文章的内容提取出来。
提取文章内容的原理也是类似的,比如我点击第二个文章:
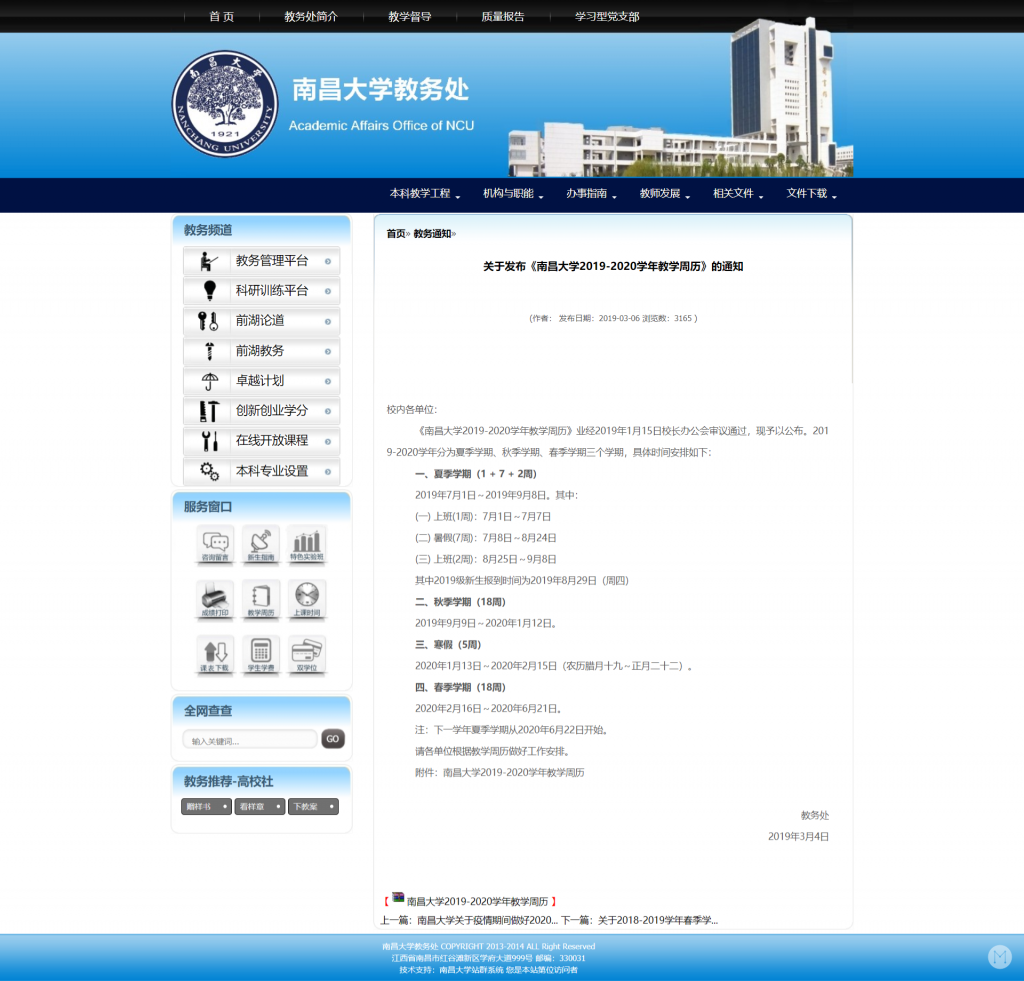
还是检查网页,不过这一次要检查的就是文章内容了。为了获取到一个完整的 RSS 内容,一般要获取以下信息:
- 文章标题
- 文章链接
- 文章内容
- 文章发布时间
这些信息在网页中都能找到。比如对于文章内容:
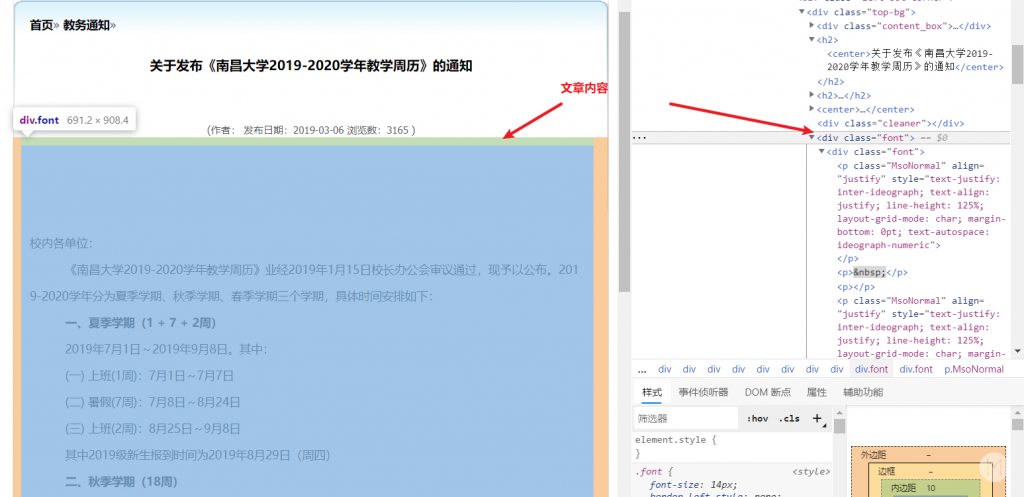
.font 类文章标题:
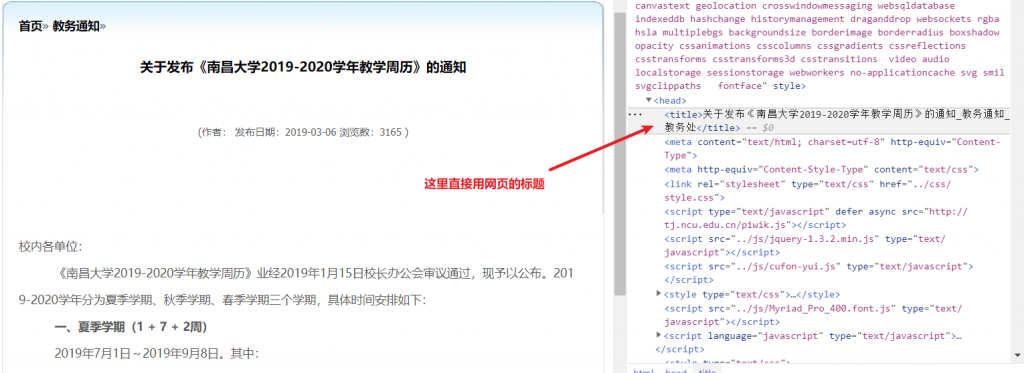
文章发布时间:
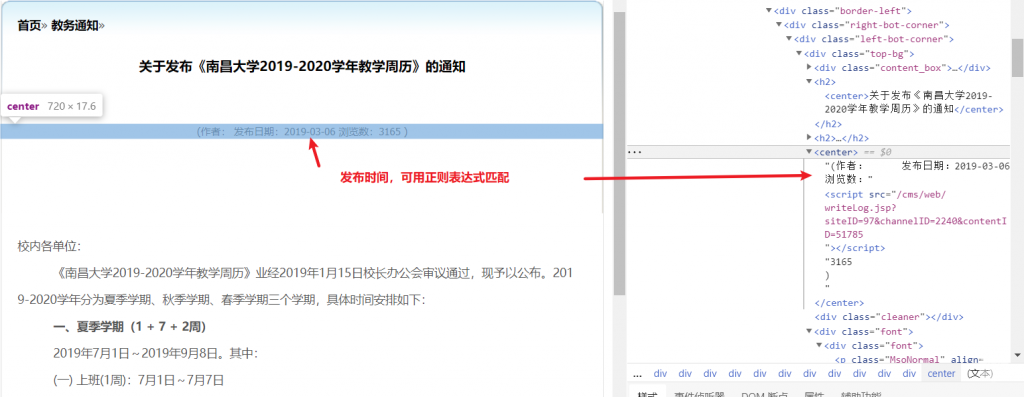
所以就可以通过下面这样的代码来实现:
// 这里没变,省略
module.exports = async (ctx) => {
// 这里也没变
const type = ctx.params.type || 'jwtz';
const link = host + map[type] + '/index.htm';
const response = await got({...});
const $ = cheerio.load(response.data);
const urlList = $('.font').find('a').slice(0, 10).map((i, e) => $(e).attr('href')).get();
const out = await Promise.all(
// ↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓
// ↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓ 下面是新增的 ↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓
// ↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓
urlList.map(async (itemUrl) => {
// 获取文章的完整链接
itemUrl = url.resolve(host, map[type] + '/' + itemUrl);
// 这里是使用 RSSHub 的缓存机制
const cache = await ctx.cache.get(itemUrl);
if (cache) {
return Promise.resolve(JSON.parse(cache));
}
// 获取列表项中的网页
const response = await got.get(itemUrl);
const $ = cheerio.load(response.data);
// single 就是一篇文章了,里面包括了标题、链接、内容和时间
const single = {
title: $('TITLE').text(), // 提取标题
link: itemUrl, // 文章链接
description: $('.font') // 文章内容,并且用了个将文章的链接和图片转成完整路径的 replace() 方法
.html()
.replace(/src="\//g, `src="${url.resolve(host, '.')}`)
.replace(/href="\//g, `href="${url.resolve(host, '.')}`)
.trim(),
pubDate: new Date(
$('center')
.text()
.match(/[1-9][0-9]{3}-[0-9]{2}-[0-9]{2}/) // 通过正则表达式来匹配时间
).toUTCString(), // 将时间的文本文字转换成 Date 对象
};
// 设置缓存及时间
ctx.cache.set(itemUrl, JSON.stringify(single), 24 * 60 * 60);
// 输出一篇文章的所有信息
return Promise.resolve(single);
})
// ↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑
// ↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑ 上面是新增的 ↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑
// ↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑
);
let info = '教务通知';
if (type === 'yxtz') {...}
ctx.state.data = {...};
}其实按理来说还应该检查一下不同 type 的网页是否结构一样的,也就是,那个“教务通知”分类下的文章页面和“院系通知”分类下的文章页面结构是否一致。如果不一致的话,还要根据分类的不同来区分抓取的代码。这里因为结构是相同的,所以就不用区分了。
现在看看完整的代码文件:
const got = require('@/utils/got');
const cheerio = require('cheerio');
const url = require('url');
// 域名
const host = 'http://jwc.ncu.edu.cn';
// 分类
const map = {
jwtz: '/jwtz',
yxtz: '/yxtz',
};
module.exports = async (ctx) => {
const type = ctx.params.type || 'jwtz';
const link = host + map[type] + '/index.htm';
// 获取列表页
const response = await got({
method: 'get',
url: link,
});
// 用 cheerio 来把请求回来的数据转成 DOM
const $ = cheerio.load(response.data);
// 提取列表项
const urlList = $('.font')
.find('a')
.slice(0, 10)
.map((i, e) => $(e).attr('href'))
.get();
// 设置一下要输出的文章项
const out = await Promise.all(
urlList.map(async (itemUrl) => {
itemUrl = url.resolve(host, map[type] + '/' + itemUrl);
// 这里是使用 RSSHub 的缓存机制
const cache = await ctx.cache.get(itemUrl);
if (cache) {
return Promise.resolve(JSON.parse(cache));
}
// 获取列表项中的网页内容,也就是一篇文章
const response = await got.get(itemUrl);
const $ = cheerio.load(response.data);
// single 就是一篇文章了,里面包括了标题、链接、内容和时间
const single = {
title: $('TITLE').text(),
link: itemUrl,
description: $('.font')
.html()
.replace(/src="\//g, `src="${url.resolve(host, '.')}`)
.replace(/href="\//g, `href="${url.resolve(host, '.')}`)
.trim(),
pubDate: new Date(
$('center')
.text()
.match(/[1-9][0-9]{3}-[0-9]{2}-[0-9]{2}/)
).toUTCString(),
};
ctx.cache.set(itemUrl, JSON.stringify(single), 24 * 60 * 60);
return Promise.resolve(single);
})
);
// 这里就是设置一下 RSS 链接显示的标题了
let info = '教务通知';
if (type === 'yxtz') {
info = '院系通知';
}
// 最后设置一下 RSS 链接里面包含的内容,item 就是输出的各个文章项
ctx.state.data = {
title: '南昌大学教务处 - ' + info,
link: link,
description: '南昌大学教务处 - ' + info + ' jwc.ncu.edu.cn',
item: out,
};
};然后在终端里运行一下看看:
npm start RSSHub所在的目录/lib/index.js
完工。
0xFF 写在最后
本文实现了通过 RSSHub 对于简单页面的抓取。但是还有一些网站是难以抓取的,比如有些网站它的网站结构是动态加载的,直接使用这样的方法无法抓取到结果。这就要用到另一个工具,叫 puppeteer,它能够模仿人浏览网页的操作,这样基本能解决各类无法抓取的问题。
等以后有空再写吧。